The concept of artificial intelligence
(AI) has been around as long as the idea of machines and computers.
People are fascinated by the idea that it is possible to code
software that can “think” to a certain extent. Technologies with
AI are all around us but we don't always think of them as AI. This
thought can be attributed to all the movies with AI that are far more
advanced than today's AI and/or that we have become used to AI being
part of the world. Examples of AI currently are robots in car
factories, automated customer services, Roomba vacuum cleaner, IBM's
Watson, and self-parking cars. Currently the two major AI areas are
voice-recognition software and self-driving cars. The major use of AI
is to improve efficiency and to help humans with dangerous or
difficult tasks. There are smart robots disabling land mines and
handling radioactive materials.
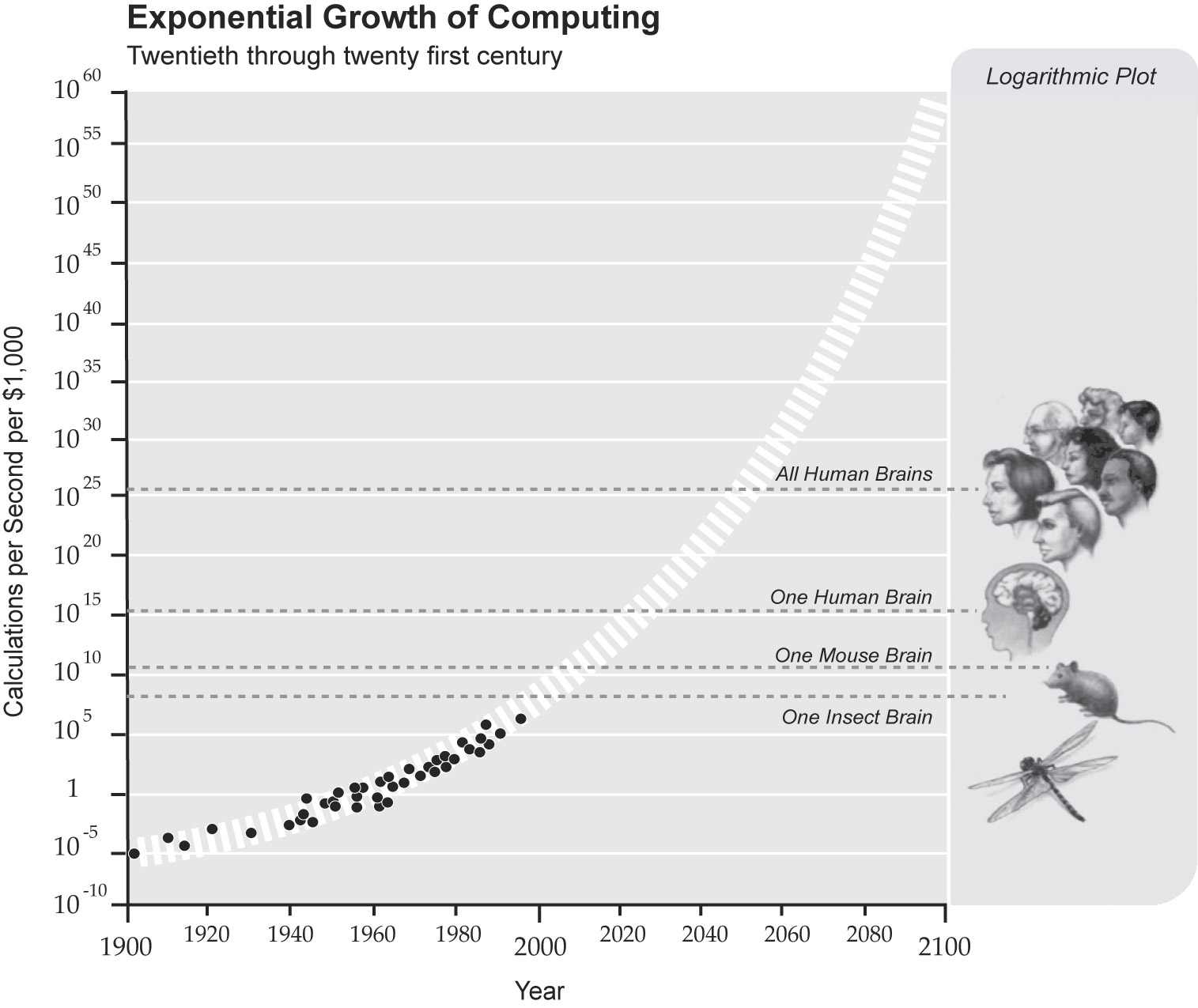
As mentioned earlier, the AI
technology available today is rather one-dimensional compared to what
one can see in movies. AI is only as smart as the code that is uses.
I don't think we are nowhere near in creating a truly “intelligent”
AI, one that has the capabilities of human thought. Whether
self-awareness can ever be achieved in a machine is debatable. One
view is that if the Moore's law continues to hold then it's only a
matter of time before humans create a machine with superhuman
intelligence. This view was brought up by Vernon Vinge and he even
went as far as saying that this will occur by the year 2030. If
mankind ever develops software that will allow a machine to analyze
data, make decisions and act autonomously then we can expect to see
machines begin to design and build even better machines. In return,
the new machines can build more powerful machines. Once these
machines are able to improve themselves humans will become obsolete
since the machines will have more intelligence then us, this point is
called technological singularity. What will happen then?
Sources:



